
스테이블 디퓨전을 들어본 적이 있다면, 아마도 당신은 이미 멋진 AI 이미지 생성 모델에 대해 알고 있을 겁니다. 오늘 자세히 알아볼 스테이블 디퓨전의 체크포인트 모델은 일반적이거나, 특정한 장르 상관없이 다양한 이미지를 생성할 수 있도록 미리 학습된 가중치를 뜻하는데, 최근 온라인 상의 다양한 AI 아트 커뮤니티에서는 독특한 체크포인트 모델을 사용해 자신만의 고유한 작품을 창조하고 있죠.
스테이블 디퓨전 체크포인트 모델의 가장 큰 매력은 무엇일까요? 바로 특정 주제나 스타일을 따르는 이미지를 쉽게 생성할 수 있다는 점입니다. 어떤 체크포인트 모델을 선택하느냐에 따라 고양이 이미지에 특화된 모델, 디지털 일러스트 스타일에 특화된 모델 등 원하는 결과물을 얻을 수 있습니다. 이를 통해 각자의 창의력을 한층 더 끌어올릴 수 있다는 사실, 흥미롭지 않나요?
체크포인트 모델이란 쉽게 말해 모델이 학습한 이미지를 바탕으로 특정 스타일이나 주제의 이미지를 생성할 수 있는 기능을 가진 프리셋이라고 할 수 있습니다. 이를 활용하면 현실적인 풍경부터 디지털 판타지, 애니메이션 스타일까지 다양한 분야의 이미지를 손쉽게 만들 수 있죠.
하지만 어떤 모델을 선택해야 할지, 어떻게 설치하고 활용할지 궁금해하는 분들도 많습니다. 오늘은 이 글을 통해 체크포인트 모델의 개념부터 다양한 모델의 특성과 활용법, 설치 방법까지 모두 다뤄보도록 하겠습니다.
미세 조정 모델이란?
스테이블 디퓨전 모델은 이미지를 생성하는 강력한 도구이지만, 모든 스타일과 주제를 완벽하게 다루지는 못합니다. 이때 필요한 것이 바로 미세 조정 모델입니다.
미세 조정이란, 이미 다양한 이미지 데이터로 학습된 기본 모델에 특정 스타일이나 주제에 맞춰 추가 학습을 시키는 기법을 말합니다. 이렇게 학습된 미세 조정 모델은 기본 모델의 다양성을 유지하면서도 특정 주제나 스타일에 더욱 편향된 이미지를 생성할 수 있게 만들어줍니다.
예를 들어, 기본 스테이블 디퓨전 모델에 ‘anime’라는 프롬프트를 입력하면 애니메이션 스타일의 이미지를 생성할 수 있지만, 특별한 장르의 애니메이션 이미지를 얻기는 어렵습니다. 이런 경우에는 프롬프트를 수정하는 것보다 해당 장르의 이미지로 모델을 미세 조정하는 것이 훨씬 효과적이죠. 그래서 많은 AI 아티스트들이 자신만의 독특한 이미지 스타일을 위해 미세 조정 모델을 활용하고 있습니다.
다음은 동일한 프롬프트와 설정을 사용하면서도 각기 다른 모델을 활용해 생성한 이미지의 예시입니다.
1. Realistic Vision
현실적이고 사실적인 이미지를 생성하는 데 특화된 모델입니다.

2. Anything v3
애니메이션 스타일의 이미지에 최적화된 모델입니다.
02.jpg&source=1girl, Best quality, genshin,Touhou Project,Honkai StarRail, ((quan (kurisu tina))),(portrait),year 2023, blue hair, white background, open hand, rabbit girl, parody, blue eyes, dress, fox ears, fine art parody, outstretched hand, long sleeves, black footwear, socks, rabbit ears, twintails, animal ears, red dress, company connection, short hair, white socks, ponytail, simple background, short twintails, masterpiece, newest, absurdres, safe
3. DreamShaper
독특한 판타지 아트 스타일을 가진 모델입니다.

이처럼 미세 조정 모델은 원하는 스타일의 이미지를 보다 쉽게 얻을 수 있게 해주는 핵심 도구가 됩니다.
미세 조정 모델을 제작하는 방법
미세 조정 모델을 만드는 것은 추가 학습과 드림부스라는 두 가지가 방법이 있습니다. 두 방법 모두 기본 모델로 스테이블 디퓨전 v1.4 또는 v1.5를 사용하며, v2 기반의 모델은 프롬프트를 활용하기 어려워 거의 사용되지 않습니다.
1. 추가 학습
추가 학습은 기본 모델에 특정 스타일이나 주제의 이미지를 추가 데이터로 학습시키는 방법입니다. 예를 들어, 스테이블 디퓨전 v1.5 모델에 빈티지 자동차 이미지 데이터 세트를 사용해 추가로 학습시키면 빈티지 자동차에 특화된 모델을 만들 수 있습니다. 이렇게 만들어진 미세 조정 모델은 특정 주제나 스타일의 이미지에 편향된 결과물을 생성할 수 있죠.
2. 드림부스
구글에서 개발한 드림부스는 텍스트-이미지 모델에 사용자 지정 피사체를 삽입하는 기술입니다. 이를 이용하면 3~5장의 이미지로도 모델을 미세 조정할 수 있으며, 특정 인물이나 사물을 모델에 쉽게 포함시킬 수 있습니다. 다만, 드림부스로 학습된 모델은 이미지에 반영하기 위한 특별한 키워드가 필요합니다.
참고로, 체크포인트 모델만이 스타일을 변경할 수 있는 것은 아닙니다. 텍스트 인버전(Textual Inversion, 또는 embedding이라고도 합니다.), LoRA, LyCORIS, 하이퍼네트워크 등을 통해서도 스타일을 변경할 수 있습니다.
널리 사용되는 스테이블 디퓨전 모델
스테이블 디퓨전 모델은 크게 v1과 v2의 두 가지 버전으로 나뉩니다. 하지만 기본 모델 외에도 수천 개의 미세 조정 모델이 존재하며, 새로운 특성을 담은 모델이 매일 출시되고 있습니다. 그중에서도 가장 널리 사용되는 두 가지 기본 모델은 다음과 같습니다.
스테이블 디퓨전 v1.4
v1.4는 이미지 생성에 특화된 첫 버전 중 하나로 많은 사용자들에게 사랑받았습니다. 이 모델은 범용적으로 사용할 수 있는 이미지 생성 모델로서 다양한 스타일과 주제를 커버할 수 있습니다.
- 모델 페이지: huggingface.co
- 다운로드: sd-v1-4.ckpt
스테이블 디퓨전 v1.5
v1.5는 v1.2를 기반으로 추가 학습된 모델로, 2022년 10월 Stability AI와 Runway ML의 파트너십을 통해 공개되었습니다. v1.4와 마찬가지로 범용 모델로 사용할 수 있으며, 두 버전 간에 큰 차이는 없지만 결과물에 약간의 차이가 있습니다.
- 모델 페이지: huggingface.co
- 다운로드 링크: v1-5-pruned-emaonly.ckpt
스테이블 디퓨전 v2 모델의 특징과 한계
Stability AI는 새롭게 향상된 스테이블 디퓨전 v2 시리즈를 공개했습니다. 현재 공개된 버전은 v2.0과 v2.1이며, 주요 변경 사항은 다음과 같습니다.
- 해상도 향상: 이제 512×512 해상도 외에도 고해상도인 768×768 버전을 사용할 수 있습니다. 이를 통해 더 높은 디테일의 이미지를 생성할 수 있죠.
- 포르노 관련 자료 제거: v2 시리즈에서는 학습 데이터에서 포르노 관련 자료를 제거하여 노골적인 이미지를 생성할 수 없도록 했습니다.
처음에는 많은 사용자들이 v2 모델로 이동할 것이라고 예상되었지만, 실제로는 그렇지 않았습니다. v2.0 모델은 v1.5에 비해 이미지 품질이 낮다는 평을 받았으며, 유명인이나 예술가의 이름과 같은 강력한 키워드 사용이 어렵다는 문제도 제기되었습니다.
v2.1 모델은 이러한 문제를 어느 정도 해결했지만, 여전히 많은 사용자가 v2.1 모델로 완전히 이동하지는 않았습니다. 이미지 품질이 약간 개선되고 예술적 스타일 생성이 편리해졌지만, 대부분의 사용자는 여전히 v1 시리즈 모델을 선호하고 있죠.
유용한 체크포인트 모델들
Realistic Vision v2
Realistic Vision v2 모델은 사실적인 이미지 생성에 특화되어 있어, 사실적인 인물과 동물 사진에 적합한 프롬프트를 사용하면 놀라운 결과를 얻을 수 있습니다.
다음은 Realistic Vision v2를 통해 생성된 이미지와 프롬프트의 예시입니다.


DreamShaper
DreamShaper는 사실적인 사진과 컴퓨터 그래픽의 중간쯤에 있는 독특한 일러스트레이션 스타일에 특화된 모델입니다.
초상화부터 판타지 아트까지 다양한 주제의 이미지를 쉽게 생성할 수 있고, 섬세하고 독창적인 표현을 만들어내는 데 탁월합니다. 모델 페이지에 따르면 Restore Face 는 사용하지 않는 게 좋다고 하네요.


SDXL
SDXL은 스테이블 디퓨전 v1.5와 v2 모델의 업그레이드 버전으로, 고해상도와 높은 품질의 이미지를 생성할 수 있는 차세대 모델입니다. 다음은 SDXL 모델의 주요 장점들입니다.
- 높은 해상도: v1.5 모델의 기본 해상도는 512×512였지만, SDXL은 [1024×1024 해상도가 기본 지원 해상도]입니다. 이를 통해 디테일이 풍부한 이미지를 쉽게 생성할 수 있습니다.
- 고품질 이미지: SDXL은 SD v1.5 모델에 비해 훨씬 나은 품질의 이미지를 생성할 수 있습니다. 텍스처와 색감이 더 정교해졌고, 복잡한 디테일도 표현할 수 있습니다.
- 문자 생성 가능: SDXL 모델은 이미지에 문자를 생성할 수 있으며, 짧은 문장은 꽤 정확하게 표현할 수 있죠. 그러나 긴 문장은 아직도 어려움이 있습니다.
- 어두운 이미지 생성 가능: SD v1.5 모델에 비해 어두운 이미지를 더욱 잘 생성할 수 있습니다. 이는 암울한 분위기나 다크 판타지 스타일을 만들 때 유용합니다.

Anything v3
Anything v3는 고품질의 애니메이션 스타일 이미지를 생성하도록 학습된 모델입니다. 이 시리즈는 v1부터 여러 버전이 있으며, v3 버전은 다양한 애니메이션 캐릭터를 만드는 데 매우 유용하죠. 다음은 Anything v3 모델을 사용해 생성된 이미지와 프롬프트 예시입니다.


ChilloutMix
ChilloutMix는 아시아계 여성을 위한 특별한 모델로, 사진과 CG를 섞은 듯한 현실적인 이미지를 생성합니다. 이 모델을 통해 신체 비율이 정확하고 매력적인 인물 사진을 만들 수 있습니다. 다음은 ChilloutMix 모델로 생성된 이미지와 프롬프트 예시입니다.

ChilloutMix 모델은 단순히 a girl과 같은 프롬프트만으로는 매력적인 이미지를 얻기 어려울 수 있습니다. ulzzang-6500-v1과 같은 텍스트 인버전을 함께 사용하거나 LoRA를 사용하면 더 나은 결과물을 얻을 수 있죠. 모델 제작자도 ulzzang-6500 embedding과 LoRA 사용을 적극 추천하고 있습니다.
Protogen v2.2
Protogen v2.2는 고급스러운 일러스트와 애니메이션 스타일 이미지를 생성하는 데 탁월한 모델입니다. 애니메이션 스타일과 일러스트 스타일 모두에 적합하며, 다음은 Protogen v2.2 모델로 생성된 이미지와 프롬프트 예시입니다.

GhostMix
GhostMix는 1990년대 애니메이션 ‘공각기동대‘를 기반으로 학습된 모델로, 사이보그와 로봇을 포함한 다양한 애니메이션 스타일 이미지를 생성하는 데 탁월합니다. 모델 페이지에 따르면, “fractal art”와 “flat color/colorful” 프롬프트를 활용하면 더욱 멋진 이미지를 얻을 수 있습니다. 다음은 GhostMix 모델로 생성된 이미지와 프롬프트 예시입니다.

Inkpunk Diffusion
Inkpunk Diffusion은 Dreambooth로 학습된 모델로, 독특한 일러스트레이션 스타일을 생성하는 데 탁월합니다. 특히 프롬프트에 간단한 키워드만 넣어도 분위기가 멋진 이미지를 만들어낼 수 있죠. 다음은 Inkpunk Diffusion 모델로 생성된 이미지와 프롬프트 예시입니다. 모델 페이지에 따르면, 이 모델을 사용할 때는 반드시 키워드 nvinkpunk를 사용해야 한다고 하네요.

모델을 다운받을 수 있는 사이트들
스테이블 디퓨전의 체크포인트 모델은 독특하고 멋진 스타일을 만드는 데 필수적입니다. 그런데, 이런 다양한 스타일의 모델을 어디에서 다운로드할 수 있을까요? 다음은 가장 많이 사용되는 두 가지 플랫폼입니다.
1. Huggingface
Huggingface는 인공지능 모델의 깃허브로 불리며, 다양한 스테이블 디퓨전 모델을 제공합니다. 몇몇 모델은 직접 사용해 볼 수 있는 기능도 지원하지만, 기술적인 내용이 많아 일반 사용자가 접근하기는 다소 어렵습니다.
2. Civitai
Civitai는 최근 가장 인기 있는 사이트 중 하나로, 수많은 스테이블 디퓨전 모델이 공유됩니다. LoRA, 하이퍼네트워크, 텍스트 인버전 등 관련 모델도 풍부하게 제공되며, 다양한 이미지 예시도 확인할 수 있어 자신만의 이미지를 구상하거나 프롬프트를 참고하는 데 유용합니다. 최근에는 Huggingface에 있는 모델도 대부분 Civitai에서 공유되고 있습니다.
스테이블 디퓨전 모델 설치 및 사용 방법
스테이블 디퓨전 모델을 설치하고 사용하려면 AUTOMATIC1111 인터페이스를 활용하는 것이 가장 간단합니다. 다음과 같은 방법으로 원하는 체크포인트 모델을 쉽게 사용할 수 있습니다.
1. 모델 설치 방법
다운로드한 모델을 아래 경로에 넣어주면 됩니다.
stable-diffusion-webui/models/Stable-diffusion/
그다음 체크포인트 드롭박스 옆에 있는 “새로 불러오기” 버튼을 누르면 모델이 나타납니다. 이때 모델의 대표 이미지를 동일한 이름으로 저장해 두면 쉽게 확인할 수 있습니다.
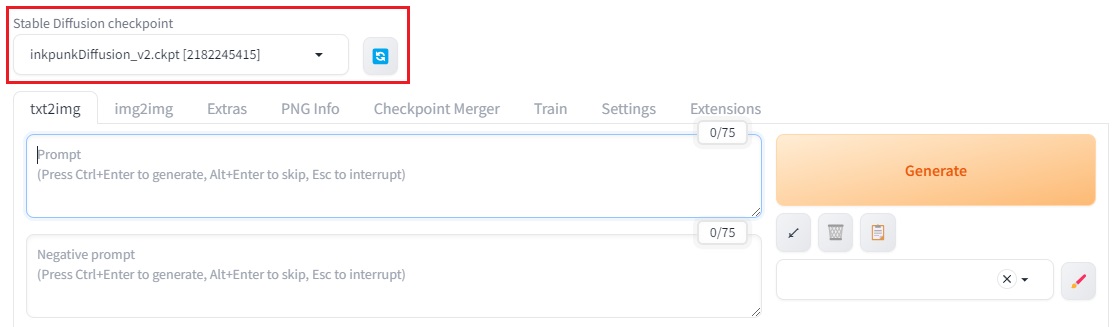
2. 모델 사용 방법
체크포인트 파일을 AUTOMATIC1111에서 사용하려면, 아래 그림처럼 왼쪽 위에 있는 드롭다운 메뉴에서 모델을 선택합니다. 방금 올린 파일이 목록에 나타나지 않으면 오른쪽의 리프레시 버튼을 눌러 새로고침한 후 드롭다운 메뉴를 사용하세요.
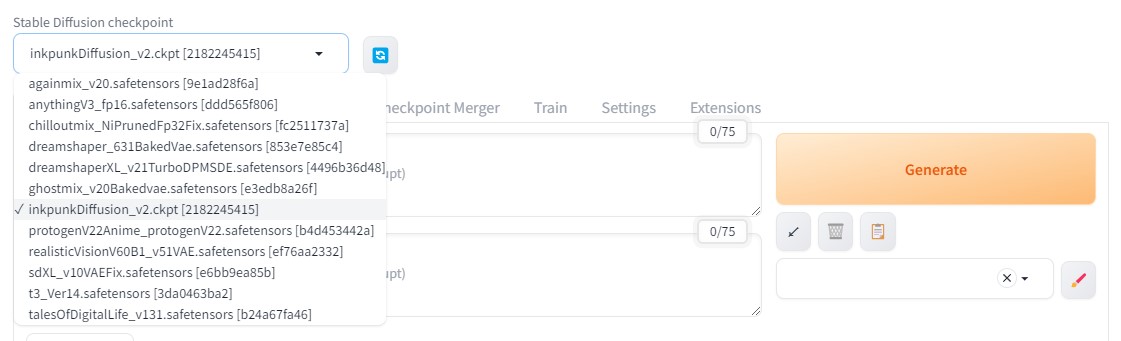
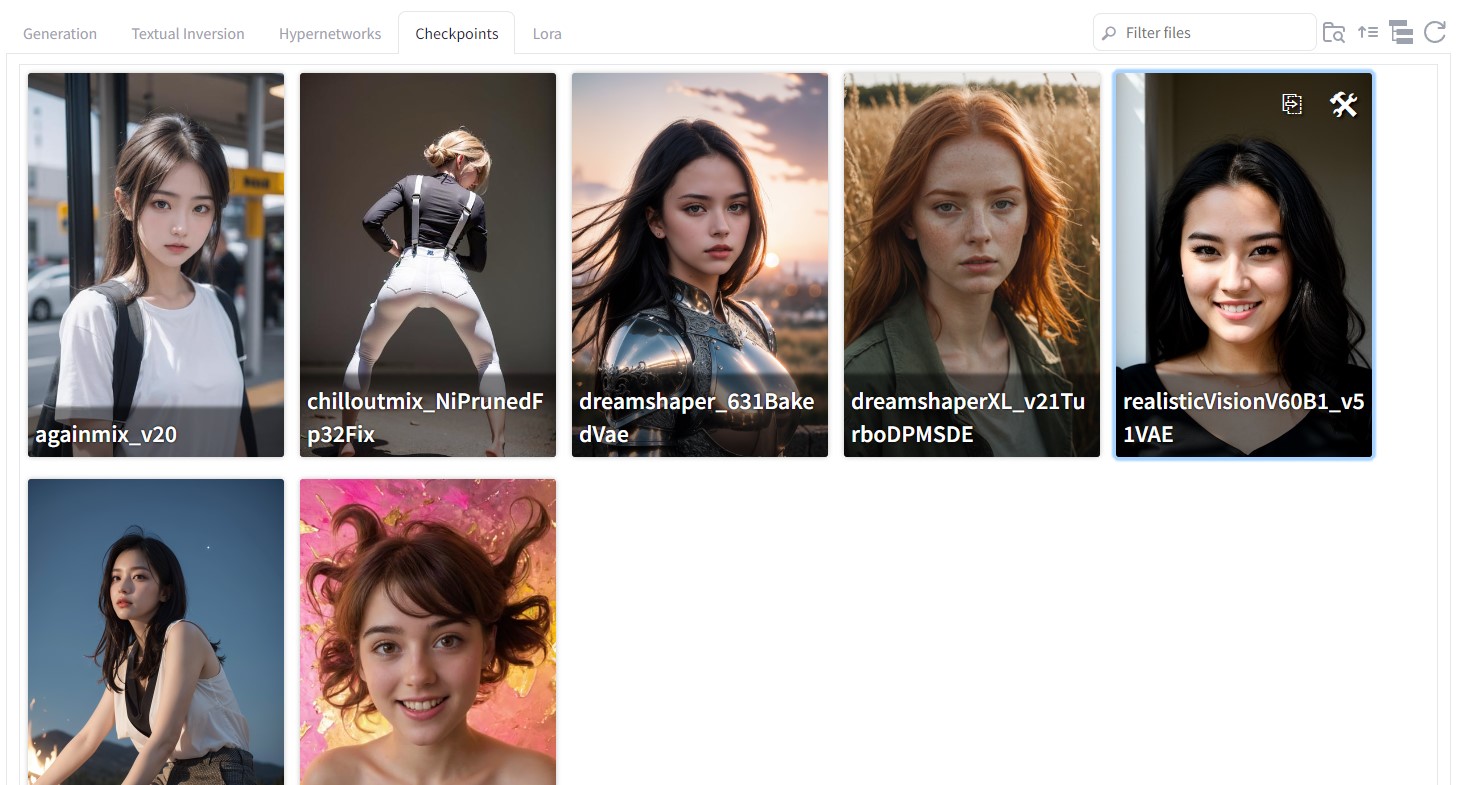
txt2img 또는 img2img 페이지에서 “Checkpoints” 탭을 눌러 원하는 모델을 선택할 수도 있습니다.
모델 합치기로 독특한 스타일 만들기
스테이블 디퓨전에서 서로 다른 모델을 합쳐 독특한 이미지를 만들어낼 수 있습니다. 이를 위해서는 AUTOMATIC1111 GUI의 Checkpoint Merger 탭을 활용하면 됩니다. 아래와 같은 방식으로 두 개의 모델을 합칠 수 있죠.
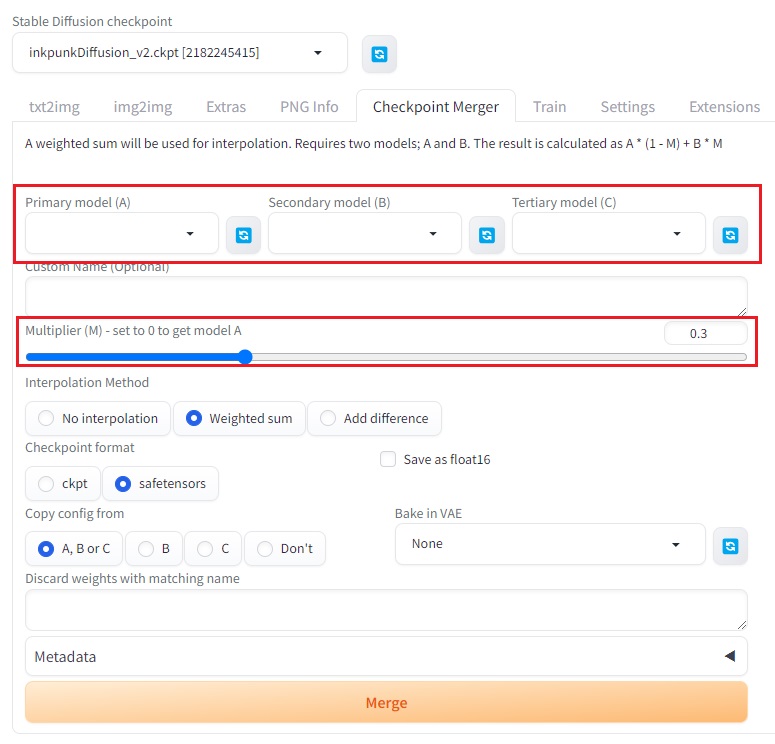
1. 모델 선택 및 설정
Checkpoint Merger 탭에서 두 개의 모델을 선택하고 다음과 같이 설정합니다. Multiplier는 두 모델이 참조되는 비율을 결정하는 가중치로, 0이면 모델 A만을 사용하고, 0.4면 A:B = 6:4 비율로 모델 A를 더 많이 참조하여 새로운 모델을 생성하는 것을 의미합니다.
2. 모델 합치기 결과 예제
아래는 Anything v3와 RealisticVision을 동일한 가중치(0.5)로 합친 결과입니다. RealisticVision는 실사 스타일이고, Anything v3는 애니메이션 스타일이기 때문에 생성된 모델은 두 스타일이 혼합된 형태입니다.

CLIP Skip으로 이미지 스타일 제어하기
CLIP Skip은 스테이블 디퓨전에서 이미지를 생성할 때 CLIP text embedding 네트워크의 마지막 레이어 몇 개를 건너뛸 수 있는 기능입니다.
CLIP은 프롬프트로 입력한 텍스트 토큰을 임베딩으로 변환하는 언어 모델로서, v1.5 모델에서 사용됩니다. AUOTMATIC1111에서 CLIP Skip 값을 조정하여 다양한 스타일의 이미지를 얻을 수 있습니다.
1. CLIP Skip 기능 이해하기
- CLIP Skip = 1: 모든 레이어를 건너뛰지 않고 사용
- CLIP Skip = 2: 마지막 레이어 한 개를 건너뛰고 사용
- CLIP Skip = 3: 마지막 레이어 두 개를 건너뛰고 사용
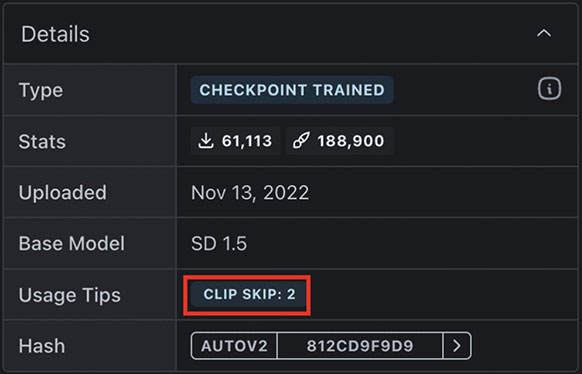
2. CLIP Skip의 효과
신경망은 레이어를 통과할 때마다 정보를 요약하며, 이전 레이어일수록 더 많은 정보가 포함되어 있습니다. 따라서 CLIP Skip 값을 높이면 프롬프트에 대한 반응이 더 강해지며, 일부 모델에서는 이미지에 극적인 변화를 가져올 수 있죠.
CLIP Skip의 예시
애니메이션 모델의 경우 CLIP Skip = 2로 학습되는 경우가 많습니다. 아래는 동일한 설정에서 CLIP Skip 값을 달리하여 생성한 이미지 예시입니다.



AUTOMATIC1111에서 CLIP Skip 설정 방법
1. Settings 페이지에서 CLIP Skip 설정하기
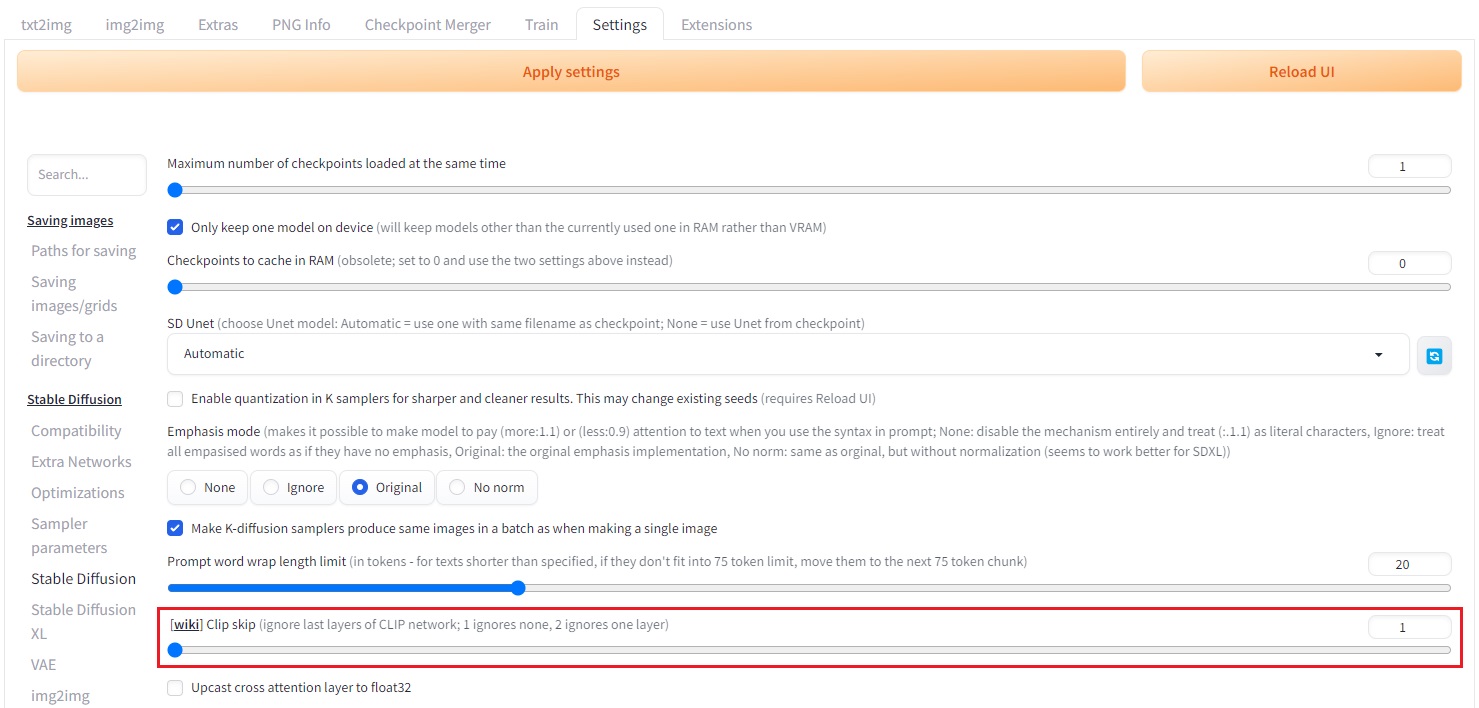
Settings 페이지에 들어가 스테이블 디퓨전 항목 아래의 Clip Skip을 찾아 원하는 값을 설정합니다. 하지만 CLIP Skip을 자주 변경해야 한다면 다음과 같은 방법을 권장합니다.
2. Quicksettings에 CLIP Skip 추가하기
- Settings 페이지에서 User Interface > Quicksettings list로 이동합니다.
- CLIP_stop_at_last_layer 항목을 추가합니다.
- Apply Settings를 누르고 Reload UI를 클릭해 인터페이스를 새로 고칩니다.
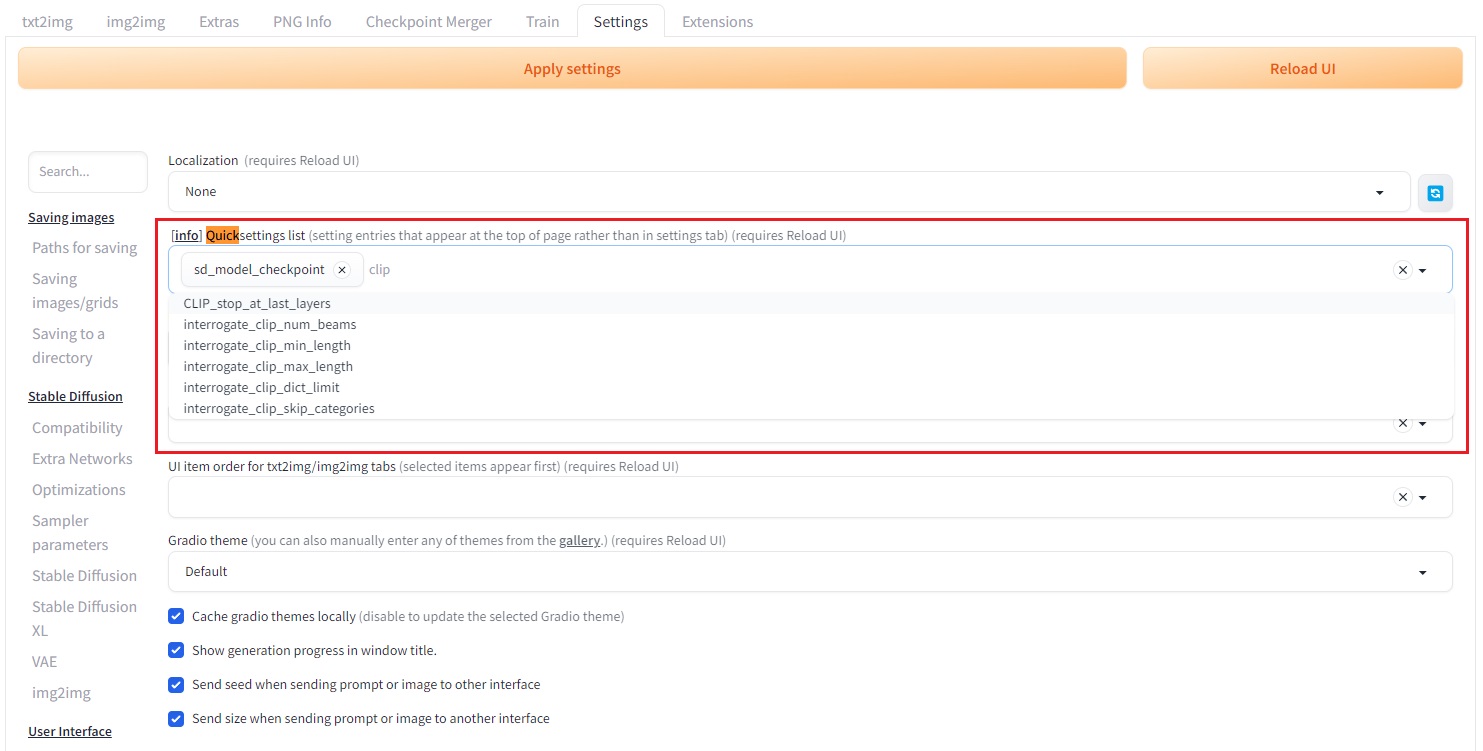
그러면 아래와 같이 AUTOMATIC1111 화면 상단에 CLIP Skip 슬라이더가 나타납니다.
스테이블 디퓨전 모델 포맷 선택 가이드
스테이블 디퓨전 모델을 다운로드할 때 다양한 파일 포맷이 제공됩니다. 각 포맷의 의미를 알고 자신의 필요에 맞는 포맷을 선택하는 것이 중요합니다.
Pruned vs Full
- Pruned: 모델의 학습에 필요한 불필요한 데이터를 제거하여 크기가 줄어든 버전입니다. 대부분의 사용자에게 적합합니다.
- Full: 모든 학습 데이터를 포함하고 있어 크기가 큽니다. 일반 사용보다는 연구나 재학습 목적으로 적합합니다.
EMA-only
모델 가중치의 지수 이동 평균 버전으로, 보다 안정적인 이미지 생성이 가능하지만 때때로 품질이 낮을 수 있습니다.
FP16 vs FP32
- FP16: Half-precision(16비트 부동소수점) 버전으로, 메모리 사용량이 적으며 속도가 빠릅니다. 대부분의 사용자에게 적합합니다.
- FP32: Full-precision(32비트 부동소수점) 버전으로, 메모리 사용량이 많지만 더 높은 정확도를 제공합니다.
참고로, 딥 러닝 모델을 위한 학습 데이터는 상당히 잡음이 많은 편입니다. 따라서 full-precision 모델이 필요한 경우는 극히 드문데, 나머지는 거의 잡음에 가깝기 때문이죠. 따라서 가능한한 FP16 모델을 사용하는 것이 좋습니다.
.pt vs .safetensors
- .pt: PyTorch 모델 포맷으로 널리 사용되지만, 취약점으로 인해 악의적인 코드를 포함할 수 있습니다.
- .safetensors: .pt의 대안으로 보안에 중점을 둔 새로운 포맷입니다. 모델을 안전하게 로드할 수 있습니다.
추천 포맷
일반적인 사용을 위해서는 Pruned FP16 버전의 .safetensors 포맷을 선택하는 것이 가장 효율적입니다. 안정성과 효율을 모두 갖춘 포맷이기 때문이죠.
마치며
스테이블 디퓨전의 체크포인트 모델을 이해하고 적절하게 활용하는 것은 AI 기반 이미지 생성의 핵심입니다. 모델을 선택할 때는 목적에 따라 Pruned와 Full 가중치 중 하나를 선택하고, 보안과 효율을 위해 Safetensors 포맷을 사용하는 것이 중요합니다.
추가로, 다양한 스타일의 체크포인트 모델과 LoRA를 결합하여 창의적인 이미지를 생성해보세요. 이미지 생성에 있어서 큰 가능성을 보여줄 수 있습니다.
- 모델 선택과 포맷: 이미지 생성만을 원한다면 Pruned 또는 EMA-only를 선택하고, 재학습이 필요하다면 Full 모델을 사용하세요.
- Safetensors: .pt 대신 보안성이 뛰어난 Safetensors 포맷을 활용하세요.
- 모델 결합: Checkpoint Merger 기능으로 서로 다른 스타일의 모델을 합쳐 새로운 스타일을 창조하세요.
- CLIP Skip: 프롬프트 반응성을 조절하여 애니메이션 모델에서는 Skip 값을 2로 설정하세요.
- LoRA: LoRA를 사용하여 세부 스타일 조정을 통해 일러스트레이션과 애니메이션 스타일을 더욱 풍부하게 만드세요.
- Huggingface vs. Civitai: Huggingface는 다양한 AI 모델을 제공하며, Civitai는 LoRA, 하이퍼네트워크 등의 세부 조정 리소스를 풍부하게 갖추고 있습니다.
오늘 살펴본 스테이블 디퓨전의 체크포인트 모델은 그 활용성과 커스터마이징 가능성에 따라 무한한 창의적 가능성을 제공합니다. 하지만 핵심은 자신만의 스타일을 만들기 위해 다양한 모델을 탐구하고, 체크포인트를 전략적으로 활용하는 것이죠. 여러분도 자신만의 스타일을 만들어 창의적이고 멋진 이미지를 만들어보시기 바랍니다.